The previous post tore down classic sinusoidal position encoding: elegant math, but its relative-position rotation property gets shredded once you add embeddings and pass through learned projection matrices. RoPE is the surgical fix: preserve geometric structure directly in the attention space instead of hoping the network rediscovers it.
You can read the original paper summary in my Paper Pulse section. This post is a systems-level reverse engineering: what rotates, why it survives the dot product, how we stretch it past training length, and where people still trip up.
TL;DR
RoPE makes relative distance an intrinsic linear algebra artifact inside the computation by rotating and in paired dimensions using position-dependent angles. After rotation: ⇒ dependence only on offset . That survives projection because the rotation is applied post-projection, not pre.
The key is about rotation
Goal: encode relative distance without an explicit learned bias matrix or extra parameters. Strategy: represent each 2D slice of the projected query/key as a complex number and rotate it by an angle proportional to absolute position. When two positions differ by , their inner product turns into a relative rotation.
We only touch and (leave alone). Additive fusion (token + position) is replaced by multiplicative geometric transformation.
Desired behavior of after positional injection:
- Stable magnitude across large absolute indices.
- Systematic phase shift proportional to .
- No need to reconstruct relative distance through learned weights.
Take two dimensional embedding as an example. Interpret as . Rotate by . In real block form this is multiplying at position with and at position with .
Inner product after rotation:
Since (orthogonal group property), we have relative-only dependence.
When dealing higher dimension embedding, we simply group the vectors in pairs, with every two dimensions forming a complex number, corresponding to a vector in the complex plane.
Relative structure persists dimension-wise. Frequencies: (original RoPE / Sinusoidal style) OR alternative bases (e.g. in many modern LLMs for longer native span). Lower ⇒ larger ⇒ faster phase advance.
Because is block-diagonal with 2×2 rotations, we can implement rotation via element-wise ops + half-swap (no full matmul):
where is Hadamard product.
Summary Snapshot
RoPE vs Sinusoidal:
- Sinusoidal: add position vector before projection → rotation structure lost after mixing.
- RoPE: rotate post-projection in paired dims → relative offset encoded algebraically in attention scores.
Implementation essentials:
- Head dim must be even (pairing).
- Rotation angle for pair : .
- geometrically decays to expand wavelength range (multi-scale coverage).
- Fast to apply: use duplicate cos/sin arrays and half-rotate op (swap + negate second half).
Benefits:
- Parameter-free.
- Cache-friendly (precompute cos/sin up to max length; slice per batch).
- Relative distance naturally emerges; no extra bias tables.
- Better length generalization than additive sinusoidal (still not magic beyond trained zone without scaling tricks).
Edge notes:
- Still sensitive to extreme lengths; phase wrapping can cause aliasing if base too small.
- High-frequency pairs degrade quicker under extrapolation; scaling methods (NTK / YaRN / Dynamic NTK) modulate frequencies.
Extrapolation
Pretraining fixes a max index . Beyond that, naive RoPE suffers phase compression and attention destabilization: high-frequency bands wrap multiple times; low-frequency ones are too smooth to differentiate far ranges.
Three families of solutions:
- Train longer (brute force): more FLOPs, memory explosion (quadratic attention cost).
- Architectural change: sparse / linear / chunked attention (changes model semantics; out-of-scope here).
- Frequency scaling hacks (what most production LLMs do): adjust mapping so effective wavelengths stretch.
Popular scaling methods:
- NTK scaling: non-linear map of position indices before rotation → matches training kernel behavior at longer lengths.
- YaRN (used in MiniMind style code below): two-region scaling; preserve low-frequency resolution, compress high-frequency to avoid aliasing.
- Dynamic/linear scaling: simple multiply of position index; crude but works for modest extension.
Why scaling works: relative phase progression is slowed so that attention similarity patterns seen during training replay over extended spans without destructive interference.
Failure modes when done wrong:
- Over-scaling → loss of local discrimination (everything looks near).
- Under-scaling → phase wrap chaos (spurious long-range attention spikes).
- Abrupt piecewise transitions → gradient shocks in fine-tuning.
I’ll deep dive comparative scaling math (NTK vs YaRN vs hybrid) in a separate post.
Implementation in MiniMind
The key component of RoPE is implemented at model/model_minimind.py:
1def precompute_freqs_cis(dim: int, end: int = int(32 * 1024), rope_base: float = 1e6,2 rope_scaling: Optional[dict] = None):3 freqs = 1.0 / (rope_base ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))4 if rope_scaling is not None:5 orig_max, factor, beta_fast, beta_slow = (6 rope_scaling.get("original_max_position_embeddings", 2048), rope_scaling.get("factor", 4),7 rope_scaling.get("beta_fast", 4.0), rope_scaling.get("beta_slow", 1.0)8 )9 if end / orig_max > 1.0:10 corr_dim = next((i for i in range(dim // 2) if 2 * math.pi / freqs[i] > orig_max), dim // 2)11 power = torch.arange(0, dim // 2, device=freqs.device).float() / max(dim // 2 - 1, 1)12 beta = beta_slow + (beta_fast - beta_slow) * power13 # λ = (β·α - β + 1)/(β·α) YaRN标准公式14 scale = torch.where(torch.arange(dim // 2, device=freqs.device) < corr_dim, (beta * factor - beta + 1) / (beta * factor), 1.0 / factor)15 freqs = freqs * scale15 collapsed lines
16
17 t = torch.arange(end, device=freqs.device)18 freqs = torch.outer(t, freqs).float()19 freqs_cos = torch.cat([torch.cos(freqs), torch.cos(freqs)], dim=-1)20 freqs_sin = torch.cat([torch.sin(freqs), torch.sin(freqs)], dim=-1)21 return freqs_cos, freqs_sin22
23
24def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):25 def rotate_half(x):26 return torch.cat((-x[..., x.shape[-1] // 2:], x[..., : x.shape[-1] // 2]), dim=-1)27
28 q_embed = (q * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(q) * sin.unsqueeze(unsqueeze_dim))29 k_embed = (k * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(k) * sin.unsqueeze(unsqueeze_dim))30 return q_embed, k_embedPre-computation of frequency
precompute_freqs_cis builds a reusable cache of for positions . Inputs:
dim: head dimension (per attention head), must be even.end: max sequence length to cache (not necessarily current batch length; can overshoot for reuse).rope_base: base for geometric progression; larger base → slower decay of → longer native span.rope_scaling: optional dict enabling length extrapolation (YaRN-style in this code).
Frequency construction
1freqs = 1.0 / (rope_base ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))- Even indices form frequency anchors.
- Larger index → smaller frequency value → longer wavelength (slower rotation).
- Geometric progression: ratio between adjacent pairs =
rope_base ** (1/dim).
YaRN scaling (optional)
Activated only if:
1if rope_scaling is not None and end / orig_max > 1.0:Steps:
orig_max: original trained max length (e.g. 2048).factor: target multiple (e.g. 4 → reach 8192).corr_dim: first frequency whose wavelength (> orig_max) triggers two-phase scaling.- Smooth schedule (slow → fast) across dims:
1power = torch.arange(0, dim//2)/ (dim//2 - 1)2beta = beta_slow + (beta_fast - beta_slow) * power- YaRN scale per dim:
1scale = ((beta * factor - beta + 1)/(beta * factor)) # for dims < corr_dim2scale = 1/factor # for dims ≥ corr_dim- Effect: retain discriminative low-frequency rotation granularity while damping high-frequency wrap risk.
- Apply:
freqs *= scale.
Expand over positions
1t = torch.arange(end)2angles = torch.outer(t, freqs) # shape: (end, dim/2)Cache cos/sin
1freqs_cos = cat([cos(angles), cos(angles)], -1)2freqs_sin = cat([sin(angles), sin(angles)], -1)Duplication restores full head_dim (each pair uses (x_even, x_odd)).
Returned: (freqs_cos, freqs_sin) of shape (end, dim).
Visual intuition
Two-region scaling: left region (lower dims) gets gentle wavelength stretch; right region (higher dims) gets uniform compression → mitigates aliasing. Diagram:
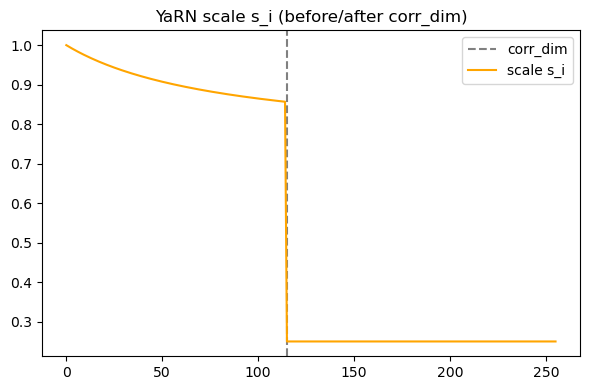
Rule of thumb: confirm no dimension’s effective wavelength collapses below typical phrase length, and no high-frequency pair wraps > ~8× within target window.
Wrap up
RoPE is a geometry-preserving positional system: cheap, deterministic, and extensible with scaling tricks. It converts “where” into controlled phase shifts instead of injected additive noise.