Introduction
The sequential order of words is crucial for natural language understanding, and while pre-trained language models (PLMs) built on the Transformer architecture have achieved state-of-the-art performance, their self-attention mechanism is inherently position-agnostic. Existing approaches to position encoding, whether absolute or relative, typically add positional information to contextual representations, which can limit flexibility and compatibility, especially with linear self-attention architectures. To address these challenges, we introduce a novel method called Rotary Position Embedding (RoPE). RoPE effectively leverages positional information by encoding the absolute position with a rotation matrix while explicitly incorporating relative position dependency within the self-attention formulation. Our proposed RoPE offers several valuable properties, including flexibility with sequence length, a natural decay of inter-token dependency with increasing relative distances, and the unique capability to equip linear self-attention with relative position encoding. We evaluate the enhanced Transformer, which we call RoFormer, on various NLP tasks, demonstrating its consistent superiority over existing alternatives. RoFormer is already integrated into Huggingface for broader use.
Rotary Position Embedding (RoPE)
Our core contribution is the Rotary Position Embedding (RoPE), a novel approach to integrate positional information into Transformer models. We formulate the problem by requiring the inner product of query $q_m$ and key $k_n$ to be a function $g$ that depends only on the word embeddings $x_m$, $x_n$, and their relative position $m-n$.
Starting with a 2D case, we derive that a solution involves rotating the affine-transformed word embedding vector by an angle proportional to its position index. We generalize this to any even dimension $d$ by dividing the $d$-dimensional space into $d/2$ sub-spaces. The position-encoded query and key vectors are then given by:
$$f_{q,k}(x_i, i) = R_{d,\Theta,i} W_{q,k} x_i$$
where $W_{q,k}$ are projection matrices and $R_{d,\Theta,i}$ is a block-diagonal rotary matrix with pre-defined parameters $\Theta = \{\theta_j = 10000^{-2(j-1)/d}, j \in [1, \dots, d/2]\}$. Each 2D block in $R_{d,\Theta,i}$ is a rotation matrix $$\begin{pmatrix} \cos(i\theta_j) & -\sin(i\theta_j) \\ \sin(i\theta_j) & \cos(i\theta_j) \end{pmatrix}$$. This means RoPE incorporates relative position information through a multiplicative rotation matrix product, rather than the additive nature of previous methods. The implementation of RoPE is visually represented in Figure 1.
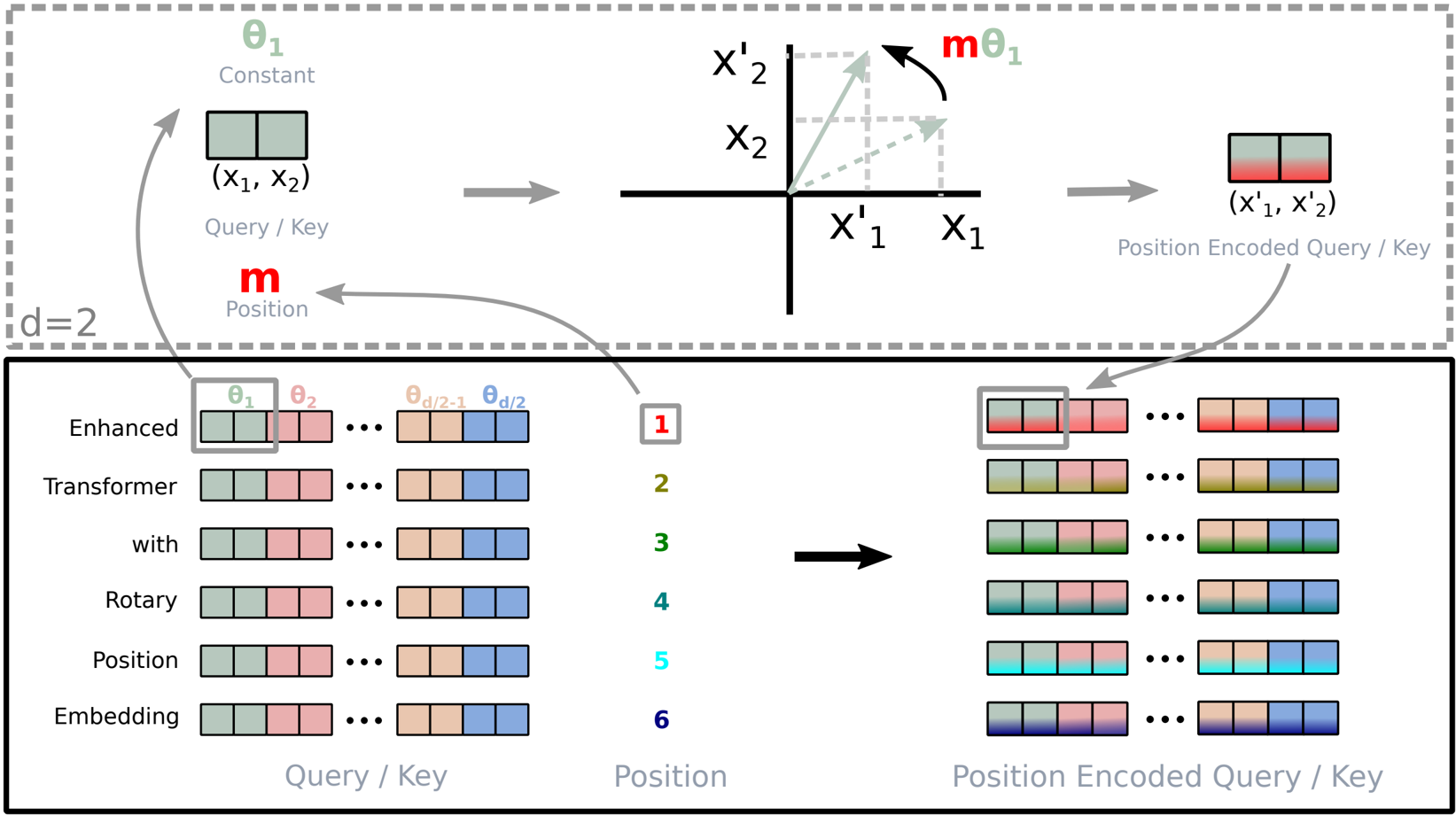
Figure 1: Implementation of Rotary Position Embedding (RoPE).
When applied to self-attention, this leads to:
$$\text{Attention}(Q, K, V) = \text{softmax}((R_{d,\Theta,m} W_q x_m)^T (R_{d,\Theta,n} W_k x_n) / \sqrt{d_k}) V$$
Since $R_{d,\Theta,i}$ is an orthogonal matrix, this simplifies to $\text{softmax}(x_m^T W_q^T R_{d,\Theta,n-m} W_k x_n / \sqrt{d_k}) V$, naturally incorporating relative position $n-m$. This orthogonality ensures stability. We also provide a computationally efficient realization of the rotary matrix multiplication due to its sparsity.
RoPE possesses key properties:
- Long-term decay: By setting $\theta_j = 10000^{-2j/d}$, the inner product between tokens decays as their relative distance increases, which aligns with the intuition that distant tokens should have weaker dependencies. This property is illustrated in Figure 2.
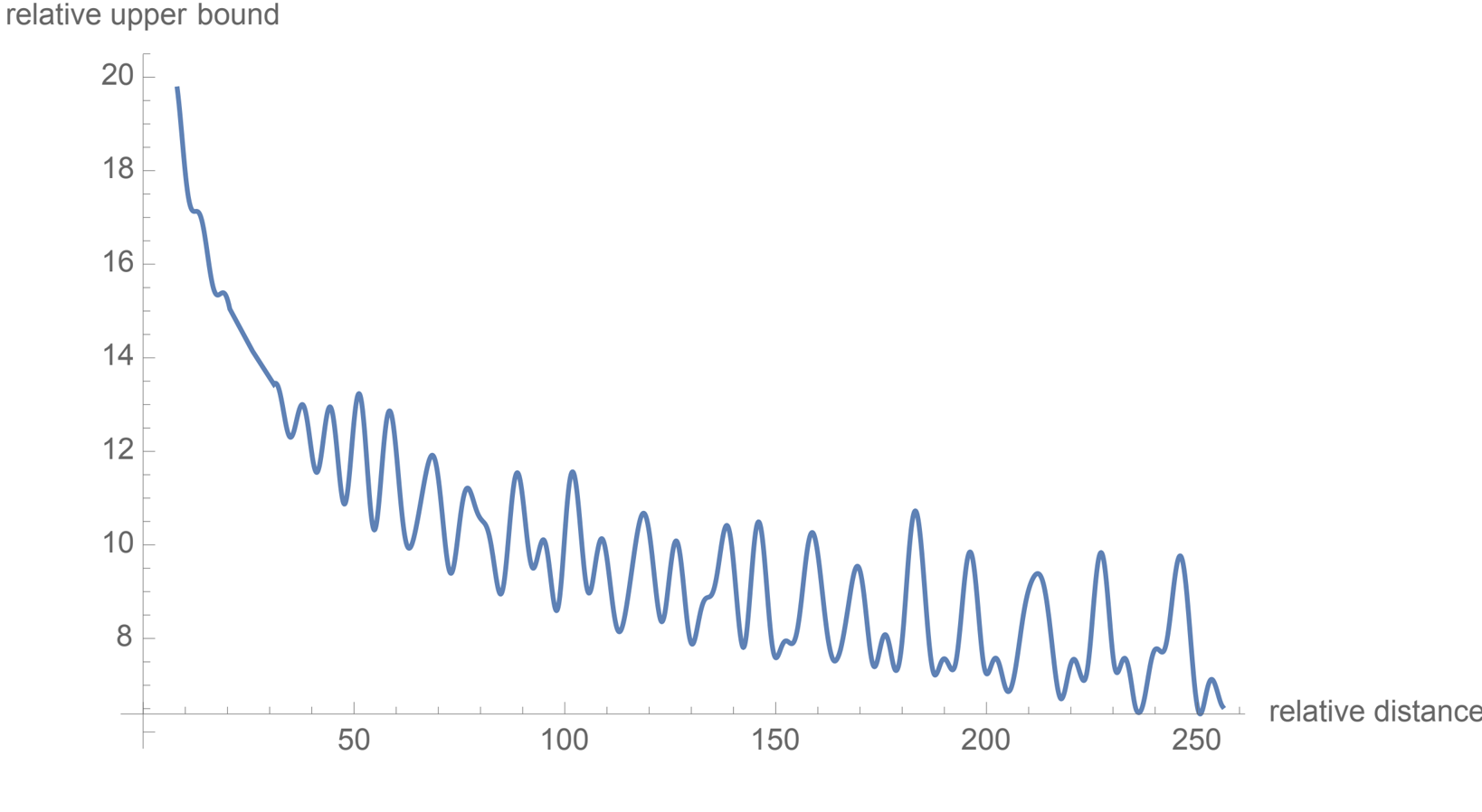
Figure 2: Long-term decay of RoPE.
- Compatibility with linear attention: RoPE injects position information through rotation, which preserves the norm of hidden representations. This allows seamless integration with linear attention mechanisms by applying the rotation matrix to the outputs of non-negative functions, maintaining linear complexity.
Experimental Design
To thoroughly evaluate RoFormer, our enhanced Transformer with RoPE, we designed a comprehensive set of experiments across diverse Natural Language Processing (NLP) tasks. Our evaluation included:
- Machine Translation: We assessed RoFormer's performance on the WMT 2014 English-to-German translation task, comparing it against the standard Transformer baseline. The primary metric was the BLEU score.
- Pre-training Language Modeling: We replaced BERT's original sinusoidal position encoding with RoPE and pre-trained RoFormer on the BookCorpus and Wikipedia Corpus. We monitored the Masked Language Modeling (MLM) loss during training to compare convergence speed and final loss values with vanilla BERT.
- Fine-tuning on GLUE Benchmarks: To evaluate generalization ability, we fine-tuned our pre-trained RoFormer on several GLUE tasks, including MRPC, SST-2, QNLI, STS-B, QQP, and MNLI. We used F1-score, Spearman correlation, and accuracy as evaluation metrics, comparing results against BERT.
- Performer with RoPE: We integrated RoPE into the Performer model, a linear attention architecture, and tested its performance on the Enwik8 dataset during language modeling pre-training. This experiment aimed to demonstrate RoPE's compatibility and benefits with linear attention, observing training loss curves with and without RoPE.
- Evaluation on Chinese Data: To validate RoFormer's efficacy on long texts, we conducted experiments on Chinese datasets, specifically the CAIL2019-SCM (Similar Case Matching) task, which involves documents often exceeding 512 characters. We pre-trained RoFormer on a large Chinese corpus and compared its performance with BERT and WoBERT, focusing on accuracy at different maximum sequence lengths.
All experiments were conducted on cloud servers equipped with 4 x V100 GPUs, ensuring consistent computational resources.
Evaluation Results
Our extensive experiments consistently demonstrated the superior performance of RoFormer across various NLP tasks:
- Machine Translation: On the WMT 2014 English-to-German translation task, RoFormer achieved a BLEU score of 27.5, slightly surpassing the Transformer-base's 27.3.
- Pre-training Language Modeling: During pre-training on BookCorpus and Wikipedia, RoFormer exhibited faster convergence and achieved lower training loss compared to BERT, indicating more efficient learning of contextual representations. This is clearly visible in the left plot of Figure 3.
- Fine-tuning on GLUE Tasks: When fine-tuned on downstream GLUE tasks, RoFormer significantly outperformed BERT on MRPC (89.5% vs 88.9%), STS-B (87% vs 85.8%), and QQP (86.4% vs 71.2%), showcasing its strong generalization capabilities. The detailed comparison is presented in Table 2.
| Model | MRPC | SST-2 | QNLI | STS-B | QQP | MNLI(m/mm) |
|---|---|---|---|---|---|---|
| BERTDevlin et al. | 88.9 | 93.5 | 90.5 | 85.8 | 71.2 | 84.6/83.4 |
| RoFormer | 89.5 | 90.7 | 88.0 | 87.0 | 86.4 | 80.2/79.8 |
- Performer with RoPE: Integrating RoPE into the Performer model for language modeling pre-training on Enwik8 led to rapid convergence and a lower final loss. This highlights RoPE's effectiveness in enhancing linear attention mechanisms, as illustrated in the right plot of Figure 3.
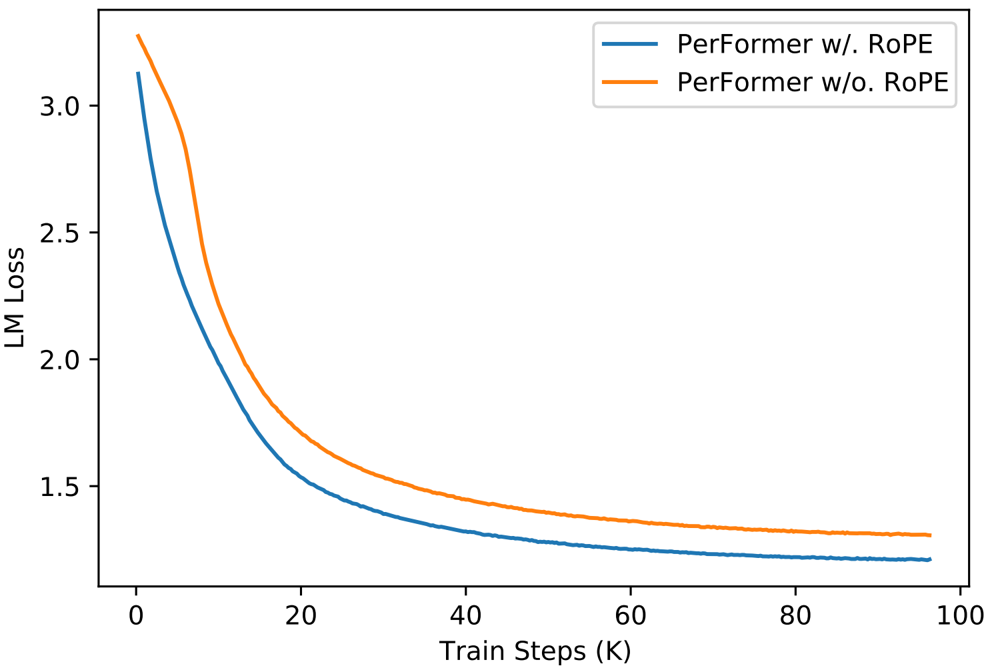
Figure 3: Evaluation of RoPE in language modeling pre-training. Left: training loss for BERT and RoFormer. Right: training loss for PerFormer with and without RoPE.
| Model | Validation | Test |
|---|---|---|
| BERT-512 | 64.13% | 67.77% |
| WoBERT-512 | 64.07% | 68.10% |
| RoFormer-512 | 64.13% | 68.29% |
| RoFormer-1024 | 66.07% | 69.79% |
- Evaluation on Chinese Data: Our pre-training strategy for RoFormer on Chinese datasets, which involved multiple stages with increasing maximum sequence lengths, showed a clear improvement in accuracy with longer inputs, confirming RoPE's excellent generalizability for long texts. Table 4 details this strategy and its impact on accuracy.
| Stage | Max seq length | Batch size | Training steps | Loss | Accuracy |
|---|---|---|---|---|---|
| 1 | 512 | 256 | 200k | 1.73 | 65.0% |
| 2 | 1536 | 256 | 12.5k | 1.61 | 66.8% |
| 3 | 256 | 256 | 120k | 1.75 | 64.6% |
| 4 | 128 | 512 | 80k | 1.83 | 63.4% |
| 5 | 1536 | 256 | 10k | 1.58 | 67.4% |
| 6 | 512 | 512 | 30k | 1.66 | 66.2% |
Furthermore, on the CAIL2019-SCM long-text matching task, RoFormer-512 achieved 68.29% accuracy, comparable to WoBERT-512 (68.10%) and BERT-512 (67.77%). Crucially, by increasing the maximum input length to 1024, RoFormer-1024 achieved 69.79% accuracy, demonstrating a significant absolute improvement of 1.5% over WoBERT and highlighting its superior capability in handling long documents, as summarized in Table 5.
Summary and Limitations
In this work, we introduced Rotary Position Embedding (RoPE), a novel position encoding method that enhances Transformer architectures by incorporating explicit relative position dependency in self-attention. Our theoretical analysis demonstrated that relative position can be naturally formulated through vector rotation, with absolute position information encoded via a rotation matrix. We mathematically illustrated RoPE's advantageous properties, including sequence length flexibility, decaying inter-token dependency, and compatibility with linear attention. Experimental results on both English and Chinese benchmark datasets consistently showed that RoFormer, our Transformer enhanced with RoPE, encourages faster convergence during pre-training and achieves superior performance, particularly on tasks involving long texts.
Despite these promising theoretical groundings and experimental justifications, our method currently has a few limitations:
- While RoFormer exhibits faster convergence than baseline models, a thorough theoretical explanation for this specific behavior, beyond the mathematical formulation of relative position, is still an area for future investigation.
- Although our model demonstrates superior performance on long texts and possesses a favorable long-term decay property for inter-token products, a more faithful and comprehensive theoretical explanation for this enhanced long-text performance is yet to be fully developed.
- As RoFormer is built upon the Transformer-based infrastructure, it inherently requires significant hardware resources for pre-training, which can be a practical constraint for some researchers and practitioners.
Cite our work
If you find this useful for your research, please consider citing our work:@article{
su2022roformer,
title={RoFormer: Enhanced Transformer with Rotary Position Embedding},
author={Su, Jianlin and Murtadha, Ahmed and Wen, Bo and Liu, Yunfeng and Lu, Yu and Pan, Shengfeng},
journal={arXiv preprint arXiv:2104.09864},
year={2022}
}