Abstract and Introduction
While Transformers have revolutionized Natural Language Processing (NLP), their application in computer vision has largely been limited to augmenting or replacing components within convolutional networks. In this work, we challenge this reliance on CNNs by demonstrating that a pure Transformer, applied directly to sequences of image patches, can achieve excellent performance on image classification tasks. Our Vision Transformer (ViT) model, when pre-trained on large datasets and then transferred to various mid-sized or small image recognition benchmarks (such as ImageNet, CIFAR-100, and VTAB), consistently matches or surpasses state-of-the-art convolutional networks. Crucially, ViT achieves these results while demanding substantially fewer computational resources for training. This success highlights that large-scale training can overcome the inductive biases inherent in CNNs, paving the way for a new paradigm in computer vision.
Vision Transformer Method
Our Vision Transformer (ViT) architecture closely follows the original Transformer design, enabling us to leverage scalable NLP Transformer implementations. To process 2D images, we first reshape an image $\mathbf{x} \in \mathbb{R}^{H \times W \times C}$ into a sequence of flattened 2D patches $\mathbf{x}_p \in \mathbb{R}^{N \times (P^2 \cdot C)}$, where $(H,W)$ is the image resolution, $C$ is the number of channels, $(P,P)$ is the patch resolution, and $N = HW/P^2$ is the number of patches. These patches are then linearly projected to a constant latent vector size $D$, forming patch embeddings.
Similar to BERT's [class] token, we prepend a learnable classification embedding to this sequence. Position embeddings are added to the patch embeddings to preserve spatial information. The resulting sequence is fed into a standard Transformer encoder, which consists of alternating layers of multiheaded self-attention (MSA) and MLP blocks. Layernorm (LN) is applied before each block, followed by residual connections. The MLP contains two layers with a GELU non-linearity. The final state of the classification token at the Transformer encoder's output serves as the image representation for classification.
$$z _ { 0 } = [ \mathbf x _ { \mathrm c l a s s } ; \, x _ { p } ^ { 1 } \mathbf E ; \, x _ { p } ^ { 2 } \mathbf E ; \cdots ; \, x _ { p } ^ { N } \mathbf E ] + \mathbf E _ { p o s }, \, \,$$ $$z _ { \ell } ^ { \prime } = \text{MSA}(\text{LN}(z _ { \ell - 1 })) + z _ { \ell - 1 }, \quad \quad \quad \ell = 1 \dots L$$ $$z _ { \ell } = \text{MLP}(\text{LN}(z ^ { \prime } _ { \ell } )) + z ^ { \prime } _ { \ell }, \quad \quad \quad \ell = 1 \dots L$$ $$\mathbf y = \text{LN}(z _ { L } ^ { 0 })$$Unlike CNNs, ViT has minimal image-specific inductive biases, relying on the self-attention mechanism to learn spatial relationships from data. For fine-tuning, we replace the pre-trained prediction head with a zero-initialized feedforward layer. We often fine-tune at higher resolutions, adapting the pre-trained position embeddings via 2D interpolation to accommodate the increased sequence length. We also explored a hybrid architecture where the input sequence is formed from CNN feature maps instead of raw image patches. Figure 1 provides a visual overview of our model.

Model overview. We split an image into fixed-size patches, linearly embed each of them, add position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder. In order to perform classification, we use the standard approach of adding an extra learnable 'classification token' to the sequence. The illustration of the Transformer encoder was inspired by Vaswani et al. (2017).
Experimental Setup
To thoroughly evaluate ViT, we conducted extensive experiments across various datasets and model configurations. For pre-training, we utilized ImageNet (1.3M images, 1k classes), its superset ImageNet-21k (14M images, 21k classes), and the large-scale JFT-300M dataset (303M high-resolution images, 18k classes). We carefully de-duplicated these datasets against downstream task test sets. For fine-tuning, we evaluated on popular benchmarks including ImageNet (original and ReaL labels), CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102, and the 19-task VTAB suite, which assesses low-data transfer with 1,000 training examples per task.
Our ViT model variants, summarized in Table 1, are based on BERT configurations: ViT-Base, ViT-Large, and an even larger ViT-Huge. We denote models by their size and patch size, e.g., ViT-L/16 for the 'Large' variant with 16x16 patches. Smaller patch sizes lead to longer sequence lengths and higher computational costs. As baselines, we used 'ResNet (BiT)' models, which are ResNets with Group Normalization and standardized convolutions, known for improved transfer learning. For hybrid models, we fed intermediate CNN feature maps into ViT, effectively using a patch size of one 'pixel' from the feature map.
| Model | Layers | Hidden size D | MLP size | Heads | Params |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
Details of Vision Transformer model variants.
All models, including ResNets, were pre-trained using Adam with specific hyperparameters ($\beta_1=0.9, \beta_2=0.999$, batch size 4096, weight decay 0.1) and a linear learning rate warmup and decay. Fine-tuning was performed using SGD with momentum and a batch size of 512. For top ImageNet results, we fine-tuned at higher resolutions (512 for ViT-L/16, 518 for ViT-H/14) and applied Polyak averaging. We report both fine-tuning and few-shot accuracies, with the latter obtained via regularized least-squares regression for efficient evaluation.
Experimental Results
Our experiments demonstrate that Vision Transformers achieve state-of-the-art performance, especially when pre-trained on large datasets. As shown in Table 2, our ViT-L/16 model, pre-trained on JFT-300M, consistently outperforms BiT-L across all tasks while requiring significantly less computational resources for pre-training. The larger ViT-H/14 further improves the performance, particularly on challenging datasets like ImageNet, CIFAR-100, and the VTAB suite, all with a lower pre-training cost than prior SOTA models. Figure 2 further breaks down VTAB performance, showing ViT-H/14's superiority on Natural and Structured tasks.
| Ours-JFT | Ours-I21k | BiT-L | Noisy Student | ||
|---|---|---|---|---|---|
| (ViT-H/14) | (ViT-L/16) | (ViT-L/16) | (ResNet152x4) | (EfficientNet-L2) | |
| ImageNet | 88.55 ± 0.04 | 87.76 ± 0.03 | 85.30 ± 0.02 | 87.54 ± 0.02 | 88.4/88.5* |
| ImageNet Real | 90.72 ± 0.05 | 90.54 ± 0.03 | 88.62 ± 0.05 | 90.54 | 90.55 |
| CIFAR-10 | 99.50 ± 0.06 | 99.42 ± 0.03 | 99.15 ± 0.03 | 99.37 ± 0.06 | – |
| CIFAR-100 | 94.55 ± 0.04 | 93.90 ± 0.05 | 93.25 ± 0.05 | 93.51 ± 0.08 | – |
| Oxford-IIIT Pets | 97.56 ± 0.03 | 97.32 ± 0.11 | 94.67 ± 0.15 | 96.62 ± 0.23 | – |
| Oxford Flowers-102 | 99.68 ± 0.02 | 99.74 ± 0.00 | 99.61 ± 0.02 | 99.63 ± 0.03 | – |
| VTAB (19 tasks) | 77.63 ± 0.23 | 76.28 ± 0.46 | 72.72 ± 0.21 | 76.29 ± 1.70 | – |
| TPUv3-core-days | 2.5k | 0.68k | 0.23k | 9.9k | 12.3k |
Comparison with state of the art on popular image classification benchmarks. We report mean and standard deviation of the accuracies, averaged over three fine-tuning runs. Vision Transformer models pre-trained on the JFT-300M dataset outperform ResNet-based baselines on all datasets, while taking substantially less computational resources to pre-train. ViT pre-trained on the smaller public ImageNet-21k dataset performs well too. * Slightly improved 88 . 5% result reported in Touvron et al. (2020).
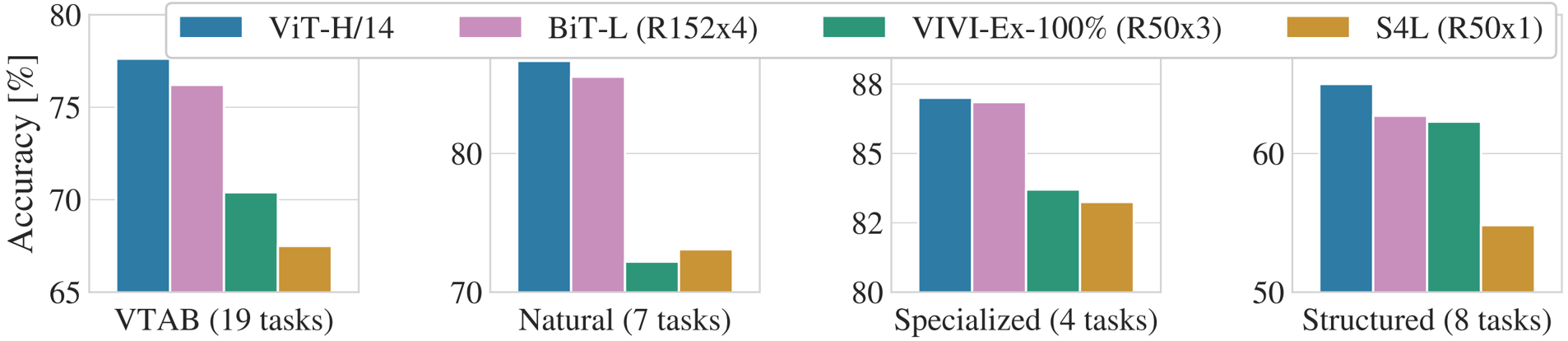
Breakdown of VTAB performance in Natural , Specialized , and Structured task groups.
We investigated the impact of pre-training data size. Figure 3 illustrates that while large ViT models underperform BiT ResNets when pre-trained on smaller datasets like ImageNet, they truly shine with larger datasets such as ImageNet-21k and JFT-300M, where they surpass CNNs. Figure 4 reinforces this, showing that ViT models overfit more than ResNets on smaller subsets of JFT-300M but perform better on larger subsets, indicating that the convolutional inductive bias is beneficial for limited data, but large-scale learning is sufficient and even advantageous for ViT.
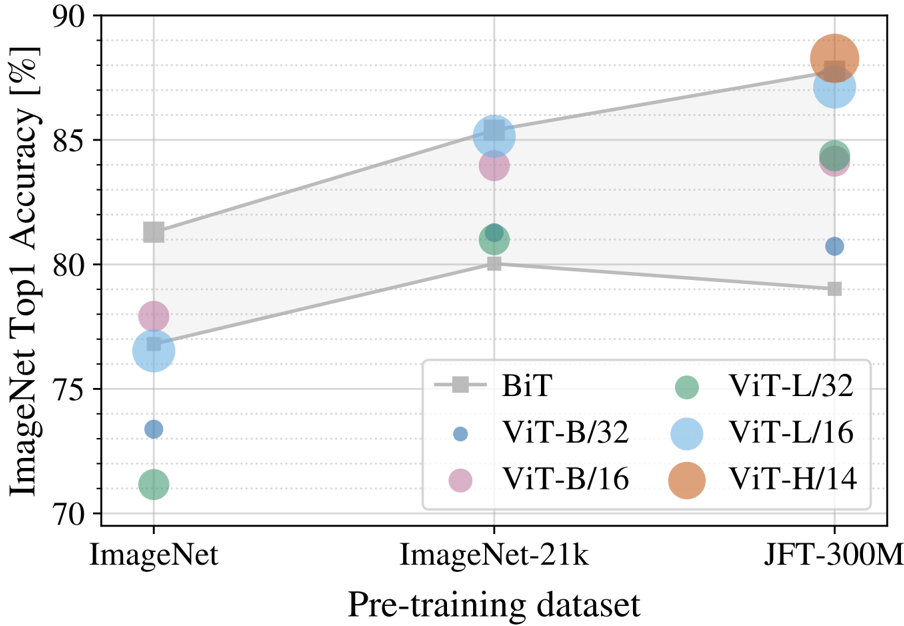
Transfer to ImageNet. While large ViT models perform worse than BiT ResNets (shaded area) when pre-trained on small datasets, they shine when pre-trained on larger datasets. Similarly, larger ViT variants overtake smaller ones as the dataset grows.
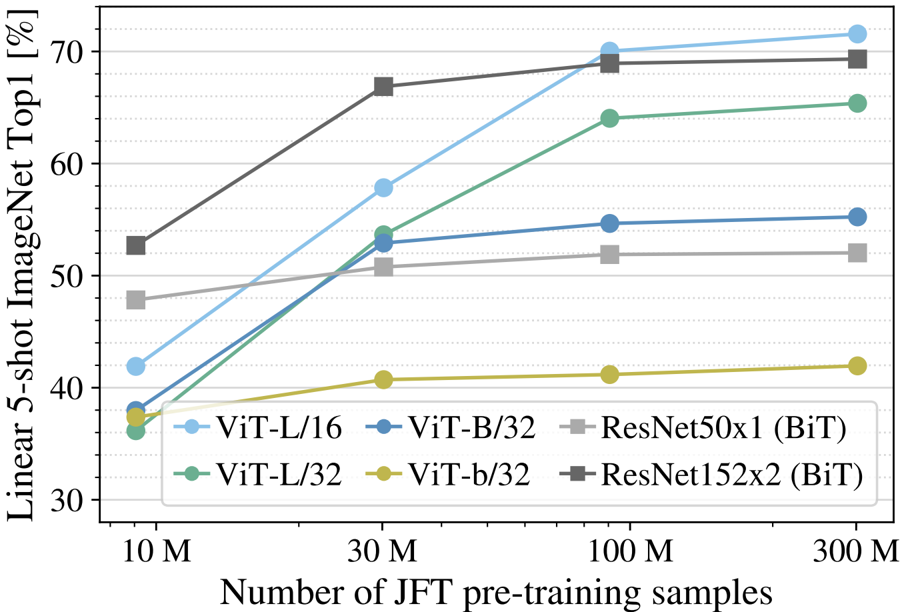
Linear few-shot evaluation on ImageNet versus pre-training size. ResNets perform better with smaller pre-training datasets but plateau sooner than ViT, which performs better with larger pre-training. ViT-b is ViT-B with all hidden dimensions halved.
Our scaling study, presented in Figure 5, reveals that Vision Transformers generally dominate ResNets in terms of performance versus pre-training compute. ViT models typically require 2-4x less compute to achieve comparable performance. While hybrid models show a slight advantage at smaller computational budgets, this gap diminishes for larger models. Importantly, Vision Transformers do not appear to saturate within the tested range, suggesting further scaling potential.
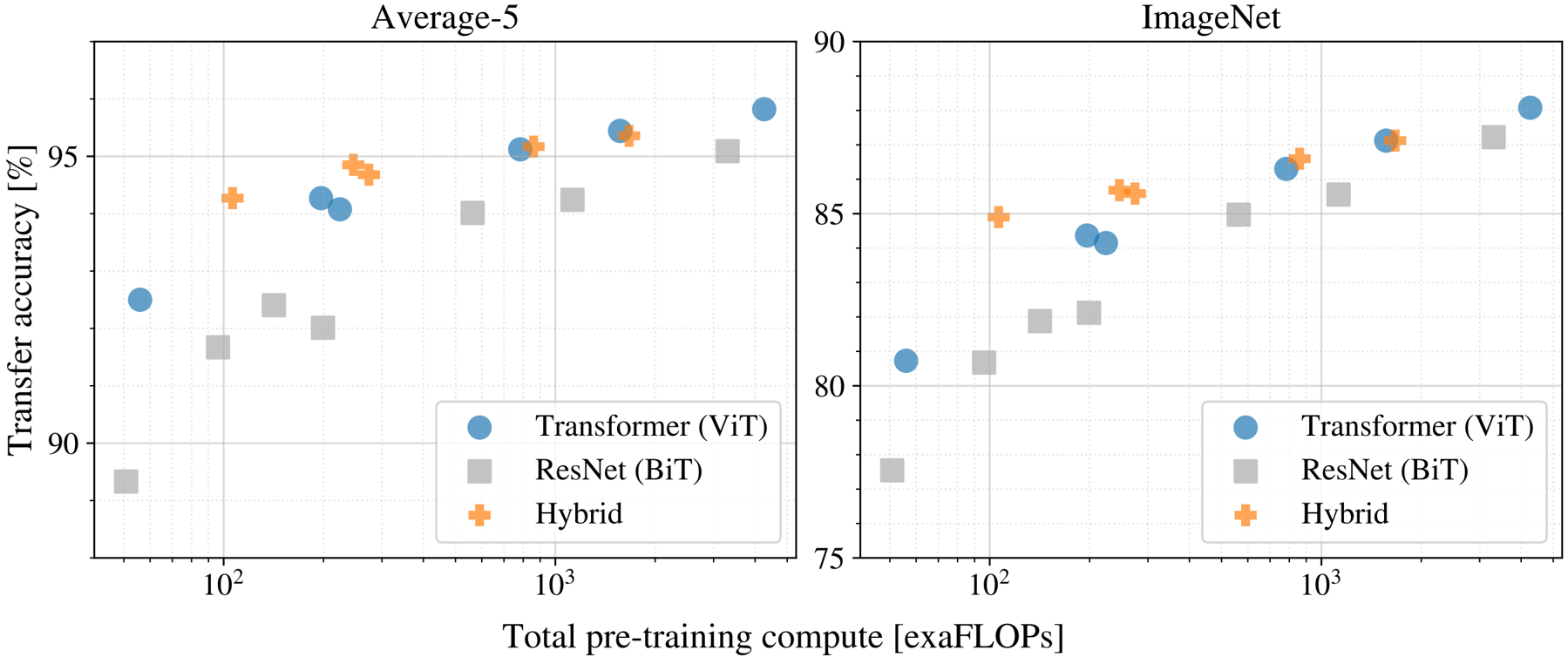
Performance versus pre-training compute for different architectures: Vision Transformers, ResNets, and hybrids. Vision Transformers generally outperform ResNets with the same computational budget. Hybrids improve upon pure Transformers for smaller model sizes, but the gap vanishes for larger models.
| name | Epochs | ImageNet | ImageNet Real | CIFAR-10 | CIFAR-100 | Pets | Flowers | exaFLOPs |
|---|---|---|---|---|---|---|---|---|
| ViT-B/32 | 7 | 80.73 | 86.27 | 98.61 | 90.49 | 93.40 | 99.27 | 55 |
| ViT-B/16 | 7 | 84.15 | 88.85 | 99.00 | 91.87 | 95.80 | 99.56 | 224 |
| ViT-L/32 | 7 | 84.37 | 88.28 | 99.19 | 92.52 | 95.83 | 99.45 | 196 |
| ViT-L/16 | 7 | 86.30 | 89.43 | 99.38 | 93.46 | 96.81 | 99.66 | 783 |
| ViT-L/16 | 14 | 87.12 | 89.99 | 99.38 | 94.04 | 97.11 | 99.56 | 1567 |
| ViT-H/14 | 14 | 88.08 | 90.36 | 99.50 | 94.71 | 97.11 | 99.71 | 4262 |
| ResNet50x1 | 7 | 77.54 | 84.56 | 97.67 | 86.07 | 91.11 | 94.26 | 50 |
| ResNet50x2 | 7 | 82.12 | 87.94 | 98.29 | 89.20 | 93.43 | 97.02 | 199 |
| ResNet101x1 | 7 | 80.67 | 87.07 | 98.48 | 89.17 | 94.08 | 95.95 | 96 |
| ResNet152x1 | 7 | 81.88 | 87.96 | 98.82 | 90.22 | 94.17 | 96.94 | 141 |
| ResNet152x2 | 7 | 84.97 | 89.69 | 99.06 | 92.05 | 95.37 | 98.62 | 563 |
| ResNet152x2 | 14 | 85.56 | 89.89 | 99.24 | 91.92 | 95.75 | 98.75 | 1126 |
| ResNet200x3 | 14 | 87.22 | 90.15 | 99.34 | 93.53 | 96.32 | 99.04 | 3306 |
| R50x1+ViT-B/32 | 7 | 84.90 | 89.15 | 99.01 | 92.24 | 95.75 | 99.46 | 106 |
| R50x1+ViT-B/16 | 7 | 85.58 | 89.65 | 99.14 | 92.63 | 96.65 | 99.40 | 274 |
| R50x1+ViT-L/32 | 7 | 85.68 | 89.04 | 99.24 | 92.93 | 96.97 | 99.43 | 246 |
| R50x1+ViT-L/16 | 7 | 86.60 | 89.72 | 99.18 | 93.64 | 97.03 | 99.40 | 859 |
| R50x1+ViT-L/16 | 14 | 87.12 | 89.76 | 99.31 | 93.89 | 97.36 | 99.11 | 1668 |
Detailed results of model scaling experiments. These correspond to Figure 5 in the main paper. We show transfer accuracy on several datasets, as well as the pre-training compute (in exaFLOPs).
To understand ViT's internal workings, we inspected its representations. The initial linear embedding filters (Figure 7, left) resemble plausible basis functions for image patches. The learned position embeddings (Figure 7, center) effectively encode 2D image topology, with closer patches having more similar embeddings, and even revealing row-column structures. Analyzing attention distances (Figure 7, right) shows that some attention heads integrate information globally even in early layers, while others maintain localized attention, potentially mimicking early convolutional layers. Overall, the model attends to semantically relevant image regions for classification, as exemplified in Figure 6.

Left: Filters of the initial linear embedding of RGB values of ViT-L/32. Center: Similarity of position embeddings of ViT-L/32. Tiles show the cosine similarity between the position embedding of the patch with the indicated row and column and the position embeddings of all other patches. Right: Size of attended area by head and network depth. Each dot shows the mean attention distance across images for one of 16 heads at one layer. See Appendix D.7 for details.

Representative examples of attention from the output token to the input space. See Appendix D.7 for details.
Finally, our preliminary exploration into self-supervised pre-training using masked patch prediction, akin to BERT's masked language modeling, yielded promising results. Our smaller ViT-B/16 model achieved 79.9% accuracy on ImageNet, a 2% improvement over training from scratch, though still behind supervised pre-training.
Conclusion and Outlook
We have successfully demonstrated the direct application of standard Transformers to image recognition. By treating images as sequences of patches and processing them with a Transformer encoder, we've shown that image-specific inductive biases, beyond the initial patch extraction, are not strictly necessary. When coupled with large-scale pre-training, our Vision Transformer (ViT) models match or exceed the state of the art on numerous image classification benchmarks, all while being more computationally efficient to pre-train. These encouraging initial results open several exciting avenues for future research. We aim to apply ViT to other computer vision tasks, such as object detection and segmentation, building on the promise indicated by our findings and related works. Further exploration and improvement of self-supervised pre-training methods are also crucial, as our initial experiments show a significant gap between self-supervised and large-scale supervised pre-training. Lastly, we anticipate that continued scaling of ViT models will lead to even greater performance gains.
Cite our work
If you find this useful for your research, please consider citing our work:@article{dosovitskiy2020image,
title={An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={arXiv preprint arXiv:2010.11929},
year={2020}
}