Visual Instruction Tuning Overview
We introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model designed for general-purpose visual and language understanding. Our work pioneers the use of language-only GPT-4 to generate multimodal language-image instruction-following data, extending the successful concept of instruction tuning to the multimodal domain. LLaVA demonstrates impressive multimodal chat abilities, often exhibiting behaviors akin to multimodal GPT-4 on unseen images and instructions. Quantitatively, it achieves an 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. Furthermore, when fine-tuned on ScienceQA, the synergy of LLaVA and GPT-4 sets a new state-of-the-art accuracy of 92.53%. To foster future research, we have constructed two challenging evaluation benchmarks and made our GPT-4 generated visual instruction tuning data, model, and code publicly available.
Instruction Data Generation
A key challenge in building multimodal assistants is the scarcity of high-quality vision-language instruction-following data. Inspired by the success of GPT models in text annotation, we developed an automatic pipeline to generate such data by leveraging ChatGPT/GPT-4. For an image, we use two types of symbolic representations to encode its visual features for a text-only GPT: (i) Captions, which describe the visual scene from various perspectives, and (ii) Bounding boxes, which localize objects and encode their concepts and spatial locations. Based on these symbolic inputs, we generate three types of instruction-following data from COCO images:
- Conversation: Multi-turn dialogues where the assistant answers diverse questions about visual content, including object types, counts, actions, and relative positions.
- Detailed description: Comprehensive and rich descriptions for an image, generated in response to specific prompts.
- Complex reasoning: In-depth reasoning questions that require a step-by-step logical process to answer.
In total, we collected 158K unique language-image instruction-following samples, comprising 58K conversations, 23K detailed descriptions, and 77K complex reasoning examples. Our experiments confirmed that GPT-4 consistently provides higher quality instruction-following data, particularly for spatial reasoning.
LLaVA Model and Training
Our LLaVA architecture is designed to effectively combine the strengths of pre-trained large language models (LLMs) and visual models. We chose Vicuna as our LLM due to its strong instruction-following capabilities. For visual encoding, we utilize the pre-trained CLIP visual encoder, ViT-L/14, which provides visual features. To connect these two powerful components, we employ a simple yet effective linear projection layer. This trainable projection matrix, denoted as $\mathsf W$, converts the visual features $\mathsf Z _ { \nu } = g ( \mathsf X _ { \nu } )$ into language embedding tokens $\mathsf H _ { \nu } = \mathsf W \cdot \mathsf Z _ { \nu }$, ensuring they share the same dimensionality as the LLM's word embedding space. This lightweight projection allows for rapid iteration in our data-centric experiments.
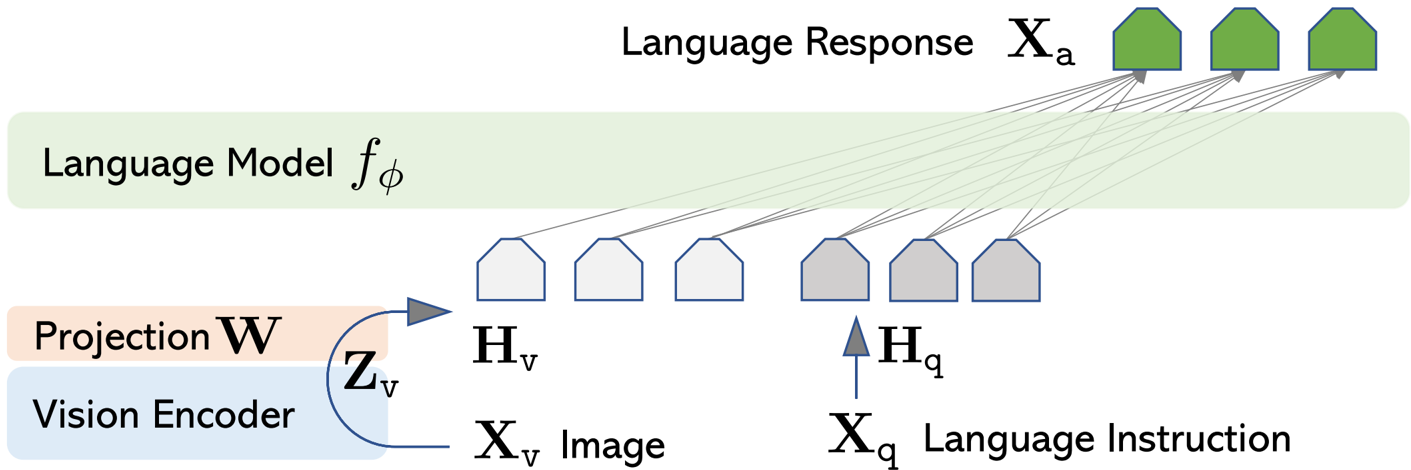
Our training procedure involves a two-stage instruction-tuning process:
Stage 1: Pre-training for Feature Alignment. We filter CC3M to create a 595K image-text pair dataset. These pairs are converted into single-turn instruction-following data, where a randomly sampled question asks for a brief image description, and the original caption serves as the ground-truth answer. In this stage, we keep both the visual encoder and LLM weights frozen, optimizing only the projection matrix $\mathsf W$ to align image features with the pre-trained LLM's word embeddings. This effectively trains a compatible visual tokenizer for the frozen LLM.
Stage 2: Fine-tuning End-to-End. With the visual encoder weights remaining frozen, we continue to update both the projection layer and the LLM's pre-trained weights. This stage is adapted for two specific use cases:
- Multimodal Chatbot: We fine-tune LLaVA on our 158K language-image instruction-following dataset, uniformly sampling from the conversation, detailed description, and complex reasoning response types.
- ScienceQA: For the ScienceQA benchmark, we organize the data as single-turn conversations, where the question and context form the instruction, and the reasoning process and answer constitute the assistant's response.
For training, we organize multi-turn conversation data into a unified sequence format, where the model is trained to predict the assistant's answers using its original auto-regressive training objective: $p ( \mathsf X _ { \mathbf a } | \mathsf X _ { \nu }, \mathsf X _ { i n s t r u c t } ) = \prod _ { i = 1 } ^ { L } p _ { \theta } ( x _ { i } | \mathsf X _ { \nu }, \mathsf X _ { i n s t r u c t, < i }, \mathsf X _ { \mathbf a, < i } )$.
Experimental Performance
We rigorously evaluated LLaVA's instruction-following and visual reasoning capabilities across two primary settings: a multimodal chatbot and the ScienceQA dataset, respectively. Our models were trained using 8 A100 GPUs, following Vicuna's hyperparameters. We pre-train our model on the filtered CC-595K subset for 1 epoch with a learning rate of 2e-3 and a batch size of 128, and fine-tune on the proposed LLaVA-Instruct-158K dataset for 3 epochs, with a learning rate of 2e-5 and a batch size of 32. See Appendix for more training details.
For the Multimodal Chatbot, LLaVA demonstrates impressive qualitative results. Even on out-of-domain images, LLaVA exhibits reasoning similar to multimodal GPT-4, accurately understanding scenes and following instructions, a notable improvement over models like BLIP-2 and OpenFlamingo which tend to merely describe images. For instance, LLaVA can identify the unusual aspects of an 'Extreme Ironing' image,

generate HTML/JS code from a sketch,

recognize visual content without explicit prompting,

and relate movie scenes to textual knowledge.

It even recognizes Elon Musk in various contexts, implying generalization to unseen visual concepts.

To quantitatively assess instruction-following, we leveraged GPT-4 as a judge to score response quality (helpfulness, relevance, accuracy, detail) on a scale of 1 to 10. We report relative scores against a text-only GPT-4 model using ground-truth textual descriptions as visual input.
- LLaVA-Bench (COCO): On this benchmark of 30 COCO images with 90 questions, instruction tuning significantly improved the model's ability to follow user instructions by over 50 points. Incorporating detailed description and complex reasoning questions led to a considerable 7-point improvement in overall capability and enhanced conversational abilities. Utilizing all three data types yielded the best performance at 85.1%.
- LLaVA-Bench (In-the-Wild): This challenging benchmark comprises 24 diverse images (indoor/outdoor, memes, paintings, sketches) and 60 questions. LLaVA achieved significantly better performance than BLIP-2 (+29%) and OpenFlamingo (+48%), with an impressive 81.7% on complex reasoning questions and an overall score of 67.3%. However, we observed limitations, such as difficulties with specific knowledge extraction (e.g., restaurant names, yogurt brands) and a tendency to perceive images as a 'bag of patches' in complex semantic scenarios.
| Conversation | Detail description | Complex reasoning | All | |
|---|---|---|---|---|
| OpenFlamingo | 19.3 ± 0.5 | 19.0 ± 0.5 | 19.1 ± 0.7 | 19.1 ± 0.4 |
| BLIP-2 | 54.6 ± 1.4 | 29.1 ± 1.2 | 32.9 ± 0.7 | 38.1 ± 1.0 |
| LLaVA | 57.3 ± 1.9 | 52.5 ± 6.3 | 81.7 ± 1.8 | 67.3 ± 2.0 |
| LLaVA† | 58.8 ± 0.6 | 49.2 ± 0.8 | 81.4 ± 0.3 | 66.7 ± 0.3 |
![ICHIRAN Ramen [source]](/papers/llava/assets/2304.08485-picture-5.png)
On the ScienceQA dataset, LLaVA achieved 90.92% accuracy, closely approaching the state-of-the-art. Interestingly, a text-only GPT-4 achieved 82.69% accuracy. We explored novel model ensembling schemes with GPT-4:
- GPT-4 complement: Using LLaVA's prediction when GPT-4 failed yielded 90.97% accuracy.
- GPT-4 as the judge: When LLaVA and GPT-4 produced different answers, GPT-4 was prompted to provide a final decision. This scheme consistently improved performance across all categories, achieving a new state-of-the-art accuracy of 92.53%. This highlights GPT-4's ability to identify cases where image context is not strictly necessary, correcting LLaVA's errors.
| Method | Subject | Context Modality | Grade | Average | |||||
|---|---|---|---|---|---|---|---|---|---|
| NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | ||
| Representative & SoTA methods with numbers reported in the literature | |||||||||
| Human | 90.23 | 84.97 | 87.48 | 89.60 | 87.50 | 88.10 | 91.59 | 82.42 | 88.40 |
| GPT-3.5 | 74.64 | 69.74 | 76.00 | 74.44 | 67.28 | 77.42 | 76.80 | 68.89 | 73.97 |
| GPT-3.5 w/ CoT | 75.44 | 70.87 | 78.09 | 74.68 | 67.43 | 79.93 | 78.23 | 69.68 | 75.17 |
| LLaMA-Adapter | 84.37 | 88.30 | 84.36 | 83.72 | 80.32 | 86.90 | 85.83 | 84.05 | 85.19 |
| MM-CoTBase | 87.52 | 77.17 | 85.82 | 87.88 | 82.90 | 86.83 | 84.65 | 85.37 | 84.91 |
| MM-CoTLarge | 95.91 | 82.00 | 90.82 | 95.26 | 88.80 | 92.89 | 92.44 | 90.31 | 91.68 |
| Results with our own experiment runs | |||||||||
| GPT-4† | 84.06 | 73.45 | 87.36 | 81.87 | 70.75 | 90.73 | 84.69 | 79.10 | 82.69 |
| LLaVA | 90.36 | 95.95 | 88.00 | 89.49 | 88.00 | 90.66 | 90.93 | 90.90 | 90.92 |
| LLaVA+GPT-4† (complement) | 90.36 | 95.50 | 88.55 | 89.05 | 87.80 | 91.08 | 92.22 | 88.73 | 90.97 |
| LLaVA+GPT-4† (judge) | 91.56 | 96.74 | 91.09 | 90.62 | 88.99 | 93.52 | 92.73 | 92.16 | 92.53 |
Our Ablation Studies on ScienceQA revealed several insights:
- Visual features: Using features before the last layer of the CLIP vision encoder (90.92%) outperformed the last layer features (89.96%).
- Chain-of-thought: While a reasoning-first strategy improved convergence speed, it contributed minimally to the final performance.
- Pre-training: This stage is crucial, as skipping it resulted in a 5.11% absolute degradation in accuracy.
- Model size: The 13B model (90.92%) demonstrated superior performance compared to the 7B model (89.84%), underscoring the importance of model scale.
Project Summary
This paper successfully demonstrated the effectiveness of visual instruction tuning, marking a significant step towards building general-purpose visual assistants. We introduced an automatic pipeline for creating high-quality language-image instruction-following data, which enabled us to train LLaVA, a large multimodal model capable of following human intent to complete diverse visual tasks. LLaVA achieved a new state-of-the-art accuracy when fine-tuned on ScienceQA and exhibited excellent visual chat capabilities when fine-tuned on multimodal chat data. Furthermore, we presented the first benchmark specifically designed to study multimodal instruction-following capabilities. This work represents an initial yet robust step in visual instruction tuning, primarily focusing on real-life applications. We hope our findings and open-source contributions will inspire future research to explore more effective methods and architectures for developing even more capable multimodal models.
Cite our work
If you find this useful for your research, please consider citing our work:@article{liu2023visual,
title={Visual Instruction Tuning},
author={Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae},
journal={arXiv preprint arXiv:2304.08485},
year={2023}
}